On-Call Management Guide: Roles, Responsibilities and Tools

Whether you're an IT manager, a DevOps professional, or a Site Reliability Engineer (SRE), the challenges of managing on-call duties are significant. The stakes are high, and downtime can cost businesses a lot; moreover, poorly managed on-call practices can lead to engineer burnout, high turnover, and decreased service reliability.
What Is On-Call Management?
On-call management ensures qualified personnel are available to respond to critical issues outside normal business hours. It involves strategic scheduling, clear escalation procedures, comprehensive workflows, and the right tools.
Effective on-call scheduling reduces downtime and improves system reliability while also maintaining engineer health and engagement. Modern organizations recognize that effective on-call management software provides a competitive advantage.
Companies like Google have proven this approach works; their SRE teams invest at least 50% of their time in engineering, with no more than 25% spent on call. This balance ensures engineers stay engaged while maintaining system reliability. Understanding this foundation becomes crucial as we examine how on-call practices have evolved over time.
The Evolution from Reactive to Proactive
Traditional on-call models viewed incident response as a necessary evil. Today, successful teams focus on preventing incidents before they even occur. By leveraging better tools, monitoring systems, and workflows, teams shift from reacting to actively preventing problems. This proactive approach ensures every alert is an opportunity for learning and system improvement.
Core On-Call Roles and Responsibilities
Our first key on-call role to cover is the Primary On-Call Engineer.
Primary On-Call Engineer
The primary on-call engineer handles the initial incident response, ensuring alerts are acknowledged and mitigation steps are initiated promptly. They monitor alerts, assess impacts, follow standard procedures, and escalate to secondary engineers when needed. A deep understanding of systems, strong troubleshooting skills, and effective communication under pressure are critical.
Secondary On-Call (Escalation Engineer)
The secondary engineer steps in when incidents surpass the primary engineer's expertise. These experts handle complex problems, make architectural decisions, and manage high-stakes situations. Secondary engineers also lead post-incident reviews to enhance future responses.
IT Managers and On-Call Program Leaders
IT managers oversee the on-call system, ensuring schedules are optimized and incidents are handled effectively. They monitor engineer health, track performance metrics, and ensure teams are adequately trained. Managers balance operational needs with the engineer's well-being to maintain a sustainable on-call program.
DevOps Teams
DevOps engineers maintain system stability, particularly during deployment issues and performance challenges. They use automated tools for proactive monitoring and troubleshooting. Their goal is to minimize incidents and reduce downtime by addressing potential issues before they escalate.
Site Reliability Engineers (SREs)
SREs focus on system reliability and performance during incidents. They identify root causes, manage complex incidents, and design long-term solutions to prevent recurrence. SREs serve as the link between development and operations, ensuring that systems remain both available and reliable during high-stress situations.
Security Engineers
Security engineers protect systems from threats, especially during on-call events. When security breaches occur, the team investigates, contains, and resolves issues to maintain the integrity of the system. Their role is crucial in preventing breaches from escalating and coordinating security improvements post-incident.
Subject Matter Experts (SMEs)
SMEs offer specialized knowledge for complex incidents. SMEs are not generally on-call but are accessible for escalation in cases where incidents require their specialized knowledge. Their insights can drastically reduce resolution times and are essential for handling high-complexity problems.
Building Effective On-Call Schedules
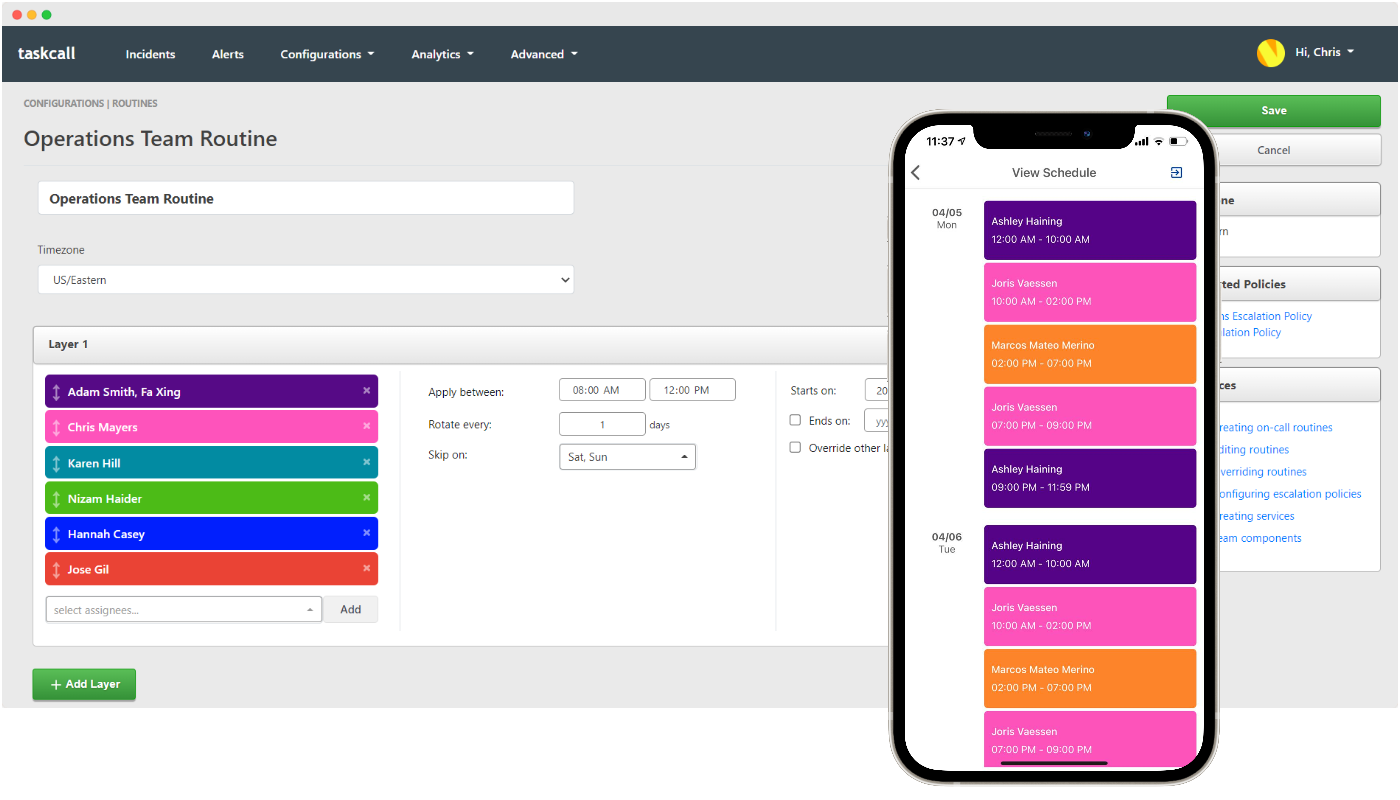
Creating fair and effective on-call schedules requires careful consideration of team dynamics, skill levels, and operational needs. A rotation model, where on-call responsibilities are shared among team members in a structured way, ensures no one is overwhelmed. Several proven rotation models have emerged from years of industry experience to balance workload and maintain optimal coverage.
Popular Rotation Models
Follow the Sun Model:
Teams in different time zones handle on-call duties during local business hours, ensuring round-the-clock coverage. This model is ideal for global organizations.
Weekly Rotation:
Engineers cover a full week of on-call shifts. It offers predictability but can be tough during high-demand periods.
Daily Rotation:
Shorter shifts that are more evenly distributed among team members, and it is ideal for larger teams or those with diverse skill sets.
Scheduling Best Practices
Fair Distribution:
Rotate shifts fairly based on skill levels and workload to prevent burnout.
Advance Notice:
Provide schedules well in advance to help engineers plan their personal activities.
Holiday Planning:
Special consideration is required during holidays, which may involve fewer staff and higher system usage.
Skill-Based Scheduling:
Match engineers' expertise to the likely incident type for efficient resolution.
Essential On-Call Management Best Practices
Building a successful on-call program requires more than just good scheduling. Organizations must implement comprehensive practices that support both effective incident response and team sustainability.
Implement Comprehensive Knowledge Bases
Your team needs access to well-maintained, comprehensive knowledge bases that include troubleshooting guides, system configurations, and recovery procedures. Having these resources readily available helps engineers resolve incidents more efficiently and reduces time spent searching for solutions during high-pressure situations.
The knowledge base should be regularly updated to reflect new solutions, processes, and lessons learned from past incidents. This resource becomes invaluable during on-call shifts, serving as both a reference guide and a training tool for new team members. Knowledge bases work best when combined with clear procedures for handling complex situations that exceed individual expertise.
Establish Clear Escalation Processes
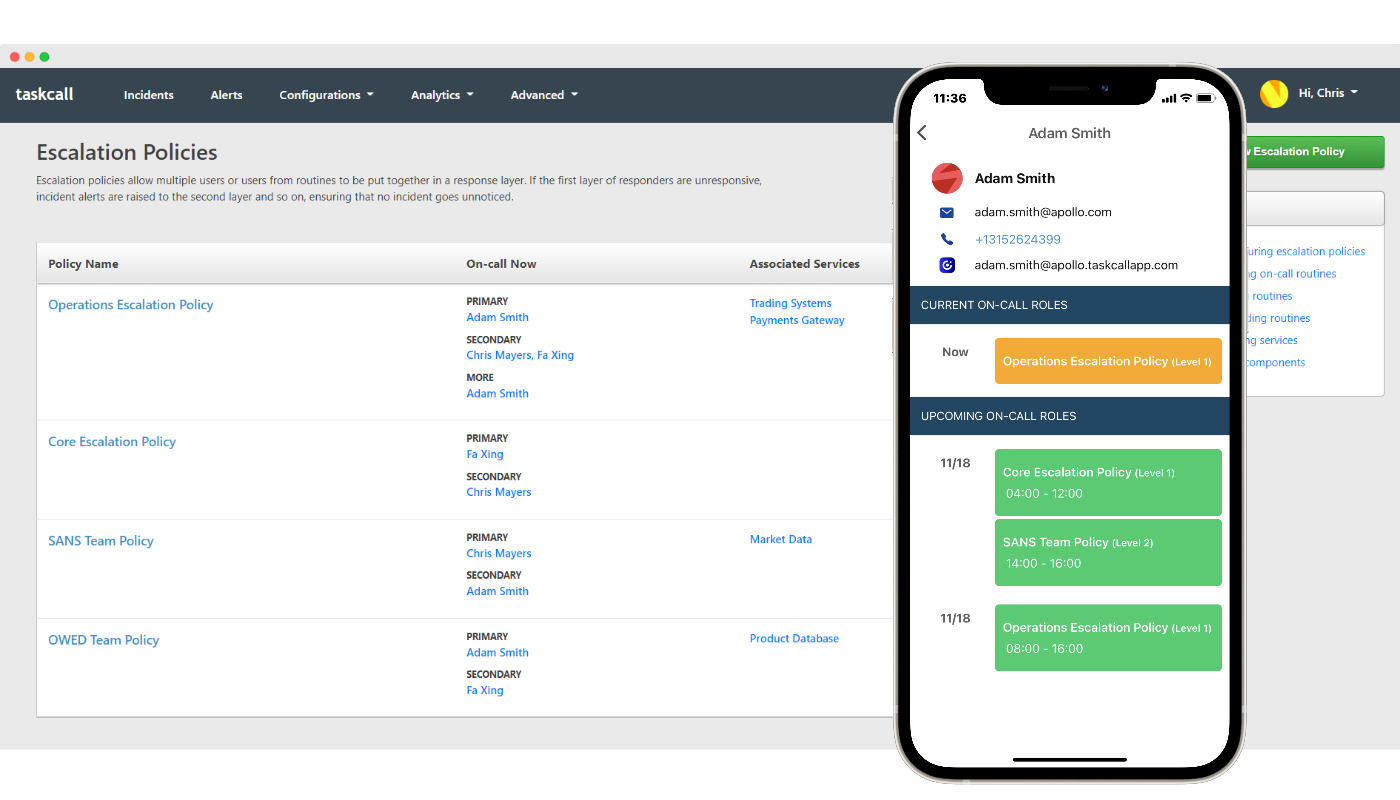
An effective escalation process is vital for handling complex issues that surpass the first responder's expertise. When incidents exceed the primary on-call's availability or capability (even though most on-call responders are equally capable), they should escalate to someone available or with specialized knowledge or higher authority. This prevents incidents from escalating further while ensuring problems get resolved as quickly as possible.
Escalation processes provide the framework for handling incidents faster, without hindering the whole process.
Conduct Post-Incident Reviews
Incident postmortem are essential for continuous improvement. After resolving incidents, teams should review situations to identify what worked well and what could improve. Regular PIRs help build learning cultures where teams enhance their processes, documentation, and overall response strategies.
These reviews should focus on systems and processes rather than individual blame. The goal is to understand why incidents occurred and how to prevent similar issues in the future. Insights from PIRs can update playbooks, improve system monitoring, or introduce new tools that enhance team effectiveness during on-call duties.
Learning from incidents helps improve future responses, but teams also need clear expectations about performance standards and response times.
Define and Monitor Service Level Agreements (SLAs)
Service Level Agreements are critical for defining expectations from on-call teams regarding response and resolution times. Clear SLAs help set realistic expectations internally and with customers, ensuring everyone understands what constitutes acceptable performance.
By monitoring SLAs during incidents, IT teams ensure they meet performance standards and deliver on commitments. SLAs also provide valuable data for future planning and process improvements. They create accountability while providing metrics that help organizations understand the effectiveness of their on-call programs.
These practices provide the operational framework, but modern on-call management also depends heavily on sophisticated tools and technologies.
Essential Tools for Modern On-Call Management
Modern on-call management relies heavily on sophisticated tooling. The right platform can mean the difference between a minor blip and a major outage. Understanding the available tools and their capabilities helps organizations make informed decisions about their technology stack.
Incident Management Platform
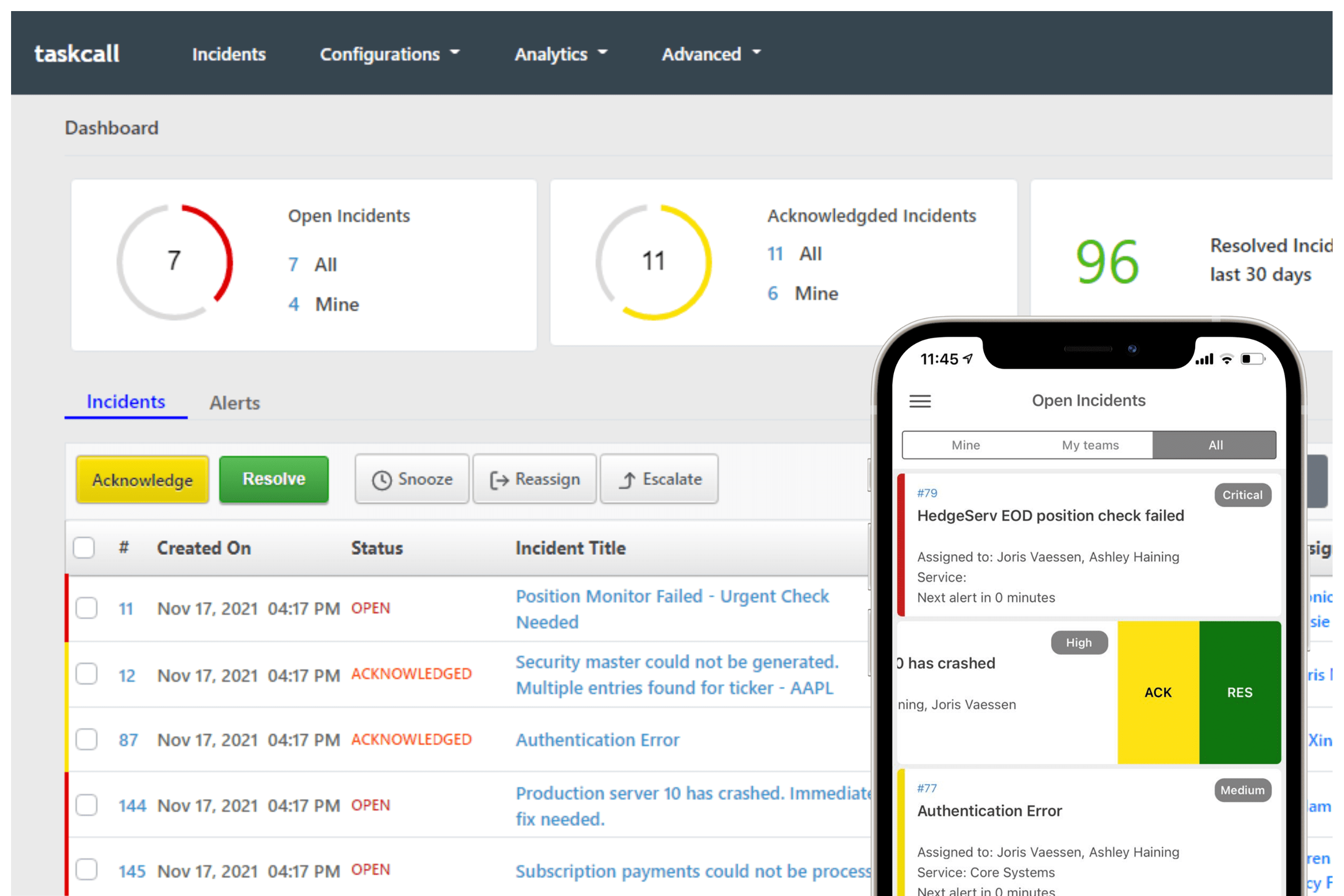
TaskCall is one of the most advanced platforms for on-call management. Designed for modern DevOps and SRE teams, it combines incident response, on-call alerting and real-time team collaboration into one seamless ecosystem. What makes Taskcall stand out is its focus on incident automation, multi-channel communication, and end-to-end transparency.
- Its real-time alert routing ensures the right people are notified instantly through voice, SMS, email, or chat integrations.
- The built-in post-incident analytics and service health dashboards help teams measure performance and continuously improve reliability.
- Unlike other platforms, Taskcall offers enterprise-grade functionality at a more accessible cost, making it an ideal solution for both growing startups and mature organizations.
In addition, Taskcall's native integrations with tools like Slack, Jira, Datadog, and AWS allow teams to connect their full observability stack without complex setup. The platform's intuitive UI and rapid incident acknowledgment system significantly reduce MTTA (Mean Time to Acknowledge) and MTTR (Mean Time to Resolve), empowering teams to operate with precision under pressure.
Monitoring and Alerting Systems
Infrastructure monitoring tools like Datadog, Amazon CloudWatch and AppDynamics provide comprehensive infrastructure visibility. They track system performance, resource utilization, and service health across your entire technology stack, giving teams the data they need to understand system behavior and identify potential issues.
Application Performance Monitoring tools focus on application-level metrics like response times, error rates, and user experience. They help identify issues before they significantly impact customers, providing early warning systems that enable proactive response.
Centralized logging systems like Splunk, ELK Stack, or Grafana Loki enable quick troubleshooting by aggregating logs from across your infrastructure. When incidents occur, having centralized logs dramatically reduces the time needed to understand what went wrong and why.
Effective monitoring generates the alerts that trigger incident response, but managing that response requires robust communication and collaboration tools.
Communication and Collaboration Tools
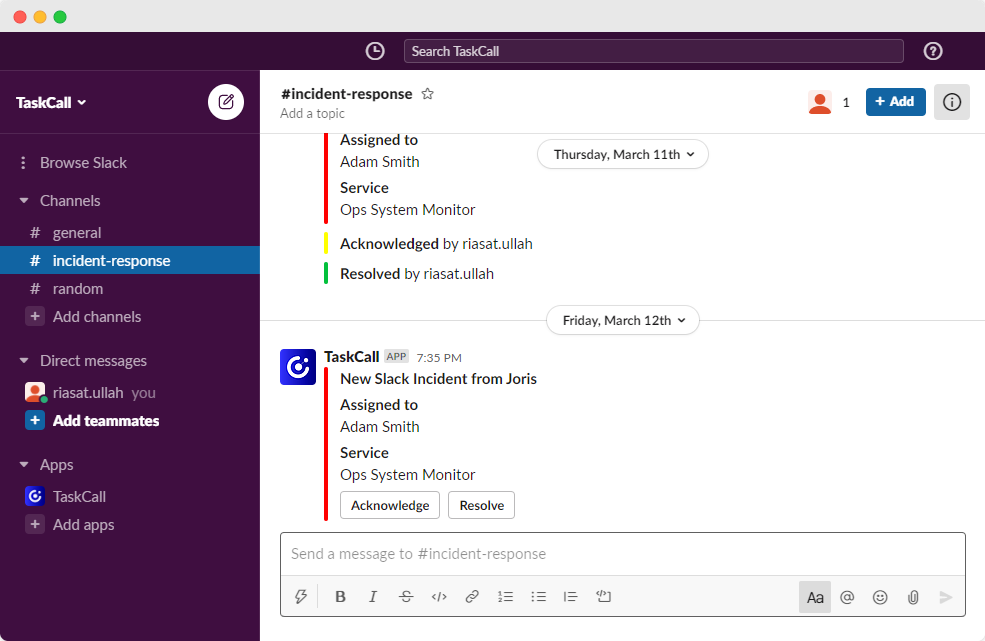
Effective communication tools are crucial for IT crisis management. Chat integration with platforms like Slack or Microsoft Teams creates seamless communication channels, ensuring transparent discussions and maintaining a searchable incident history. This integration allows teams to coordinate where they already communicate, reducing friction and enhancing team collaboration.
For major incidents, video conferencing becomes essential when distributed teams need to manage complex responses. Tools should integrate smoothly with incident management platforms, allowing teams to escalate from text-based coordination to face-to-face collaboration when the situation demands real-time, in-depth interaction.
Public Status pages provide customers with real-time updates during incidents, reducing support ticket volume and maintaining customer trust during outages. Proactive communication is key, keeping customers informed can significantly impact whether they remain loyal or look elsewhere during difficult situations.
Having the right tools creates the foundation for effective on-call management, but organizations need clear metrics to understand how well their programs are performing.
Measuring On-Call Program Effectiveness
Understanding whether your on-call program works effectively requires careful measurement of both operational performance and team health indicators. These metrics guide program improvements and help identify potential problems before they become serious issues.
Key Performance Indicator
Mean Time to Acknowledge (MTTA): Mean Time to Acknowledge measures the average time between alert generation and an engineer's. It measures how quickly an engineer acknowledges an alert. Faster response times are critical for minimizing the impact of incidents.
Mean Time to Resolution (MTTR): Tracks the time from incident detection to resolution. It reflects overall incident response effectiveness.
Alert Volume and Noise Ratio: High alert volumes with many false positives can lead to burnout. Monitoring this helps prevent alert fatigue.
Burnout Prevention Metrics
Alert Frequency per Engineer: Tracks how many alerts each engineer handles during a shift. Excessive volumes can lead to burnout.
After-Hours Work Distribution: Ensures on-call duties are fairly distributed and not overly burdensome.
Time Between Shifts: Engineers need adequate recovery time between shifts to avoid exhaustion and burnout.
Common Challenges and Practical Solutions
Even well-designed on-call programs encounter predictable challenges. Understanding these common problems and their solutions helps organizations proactively address issues before they undermine program effectiveness.
Alert Fatigue
Alert fatigue occurs when engineers become desensitized to an overwhelming number of alerts, leading to a diminished response to critical notifications. This phenomenon can result in delayed reactions to important incidents and increased risk of overlooking critical issues.
- Alert Grouping: Combine related alerts to a single alert to reduce the number of notifications.
- Alert Threshold Tuning: Regularly review and adjust alert thresholds to minimize false positives.
- Progressive Alerting: Start with low-priority alerts and escalate if issues persist, reducing unnecessary noise.
Knowledge Silos
When only certain engineers can handle specific incidents, it creates knowledge silos. To address this:
- Comprehensive Runbooks: Ensure all engineers have access to detailed procedures for handling incidents.
- Knowledge Sharing: Encourage knowledge transfer through pair programming and documentation.
Cross-Team Dependencies
Modern architectures often require multiple teams to respond to incidents, which can slow response times. Solutions include:
- Clear Escalation Paths: Define when and how to involve other teams in an incident.
- Unified Communication Platforms: Use platforms that provide a single source of truth and ensure all teams are aligned.
Advanced Strategies for Mature Organizations
Organizations with established on-call programs can implement sophisticated strategies that further reduce operational burden while improving system reliability. These advanced approaches require significant investment but can provide substantial returns for organizations ready to make that commitment.
Automated Incident Response
Automation can handle routine incidents and reduce the on-call workload. Examples include:
- Self-Healing Systems: Automatically detect and resolve issues like scaling during traffic spikes.
- Automated Runbooks: Execute standard troubleshooting steps without human intervention.
- ChatOps: Integrate incident management into chat platforms for seamless coordination and resolution.
Building Sustainable Culture
To maintain a sustainable on-call program, organizations should:
- Provide Training in Stress Management: Teach engineers to handle stress, communicate effectively, and make quick decisions under pressure.
- Recognize and Compensate On-Call Work: Offer additional pay or time off for after-hours work to acknowledge the additional responsibility.
- Promote Continuous Learning: Treat each incident as a learning opportunity to improve systems, processes, and team performance.
Future Trends Shaping On-Call Management
The on-call management landscape continues evolving rapidly, driven by technological advances and changing organizational needs. Understanding these trends helps organizations prepare for future challenges and opportunities.
AI and Machine Learning Integration
Artificial intelligence increasingly plays essential roles in incident management through predictive analytics, automated triage, and intelligent alerting systems. Recent developments include AI-assisted alert noise reduction systems that filter genuine incidents from false positives and machine learning models that predict incident likelihood based on system metrics and historical patterns.
These technologies show promise for reducing human workload while improving incident detection and response. However, they require significant data and expertise to implement effectively, making them more suitable for larger organizations with mature on-call programs.
Developer Experience Focus
Organizations increasingly focus on developer experience in on-call programs, recognizing that better tools, clearer procedures, and comprehensive support systems make on-call work less stressful and more effective. This trend reflects growing awareness that sustainable on-call programs must serve both operational needs and engineer well-being.
Implementation Roadmap for Success
Building an effective on-call management program requires a systematic approach:
- Assessment (Weeks 1-2): Audit existing on-call practices, survey team satisfaction, and identify immediate improvements.
- Foundation (Weeks 3-6): Select and implement core incident management platforms, define roles, and create standard operating procedures.
- Optimization (Weeks 7-12): Tune alert thresholds, implement automation, and measure key performance indicators.
- Maturation (Months 4-6): Review processes, implement advanced automation, and foster continuous improvement.
Final Thought
On-call management is vital for ensuring system reliability while protecting the well-being of engineers. Effective programs require thoughtful planning, the right tools, and a balance between operational needs and team health. By focusing on continuous improvement, leveraging automation, and prioritizing engineer well-being, organizations can create on-call systems that enhance both service reliability and team satisfaction.
Frequently Asked Questions
Why is proactive on-call management important?
Proactive on-call management helps teams identify and address potential issues before they escalate. By leveraging monitoring systems and automation, teams can prevent incidents, improve system performance, and reduce the need for reactive incident handling, ultimately increasing reliability and reducing downtime.
What are the core roles in on-call management?
Core roles include the Primary On-Call Engineer, who handles initial incidents, and the Secondary Engineer, who addresses complex problems. IT managers oversee scheduling and team health, while DevOps Engineers and SREs maintain system stability. Security Engineers focus on protecting systems, and SMEs offer specialized knowledge during escalations.
What is the impact of alert volume on engineer burnout?
Excessive alert volume can overwhelm engineers, leading to burnout and reduced effectiveness. By fine-tuning alert thresholds, grouping related alerts, and reducing false positives, organizations can minimize alert noise, ensuring engineers are only alerted to critical issues, which helps reduce stress and fatigue.
How do DevOps teams contribute to on-call management?
DevOps teams play a key role in maintaining system stability and ensuring that the systems are resilient to issues during deployments. They proactively monitor infrastructure, implement automation, and collaborate with on-call engineers to resolve performance and scalability issues quickly.
You may also like...
Incident response is the process of addressing technical issues that occur in a company. It could be business application errors, database issues, untested deployment releases, maintenance issues or cyber-security attacks. Automation allows such incidents to be resolved fast and save losses.
Live Call Routing allows incoming calls to be directed to your on-call personnel and makes sure you never miss an urgent matter. They can be working remotely or could step out of the office without you having to worry about customer calls going unattended.