Minimize Interruptions with Smart Alert Management
Developers spend a significant portion of their day working on incidents. Every interruption is a distraction away from their development projects and slows down the development cycle. TaskCall ensures that interruptions are reduced to the minimum by bringing alert sense to incident response, identifying repeating alerts and content based suppression. Developers can define their own suppression rules and stop excess noise before they render into incidents. AI enabled alert grouping is also available to ascertain similarities and merge them into one incident and avoid pinging developers when they are already on the case. Let developers spend more time on development rather than maintenance.
Detect and Resolve Incidents Before Client Impact
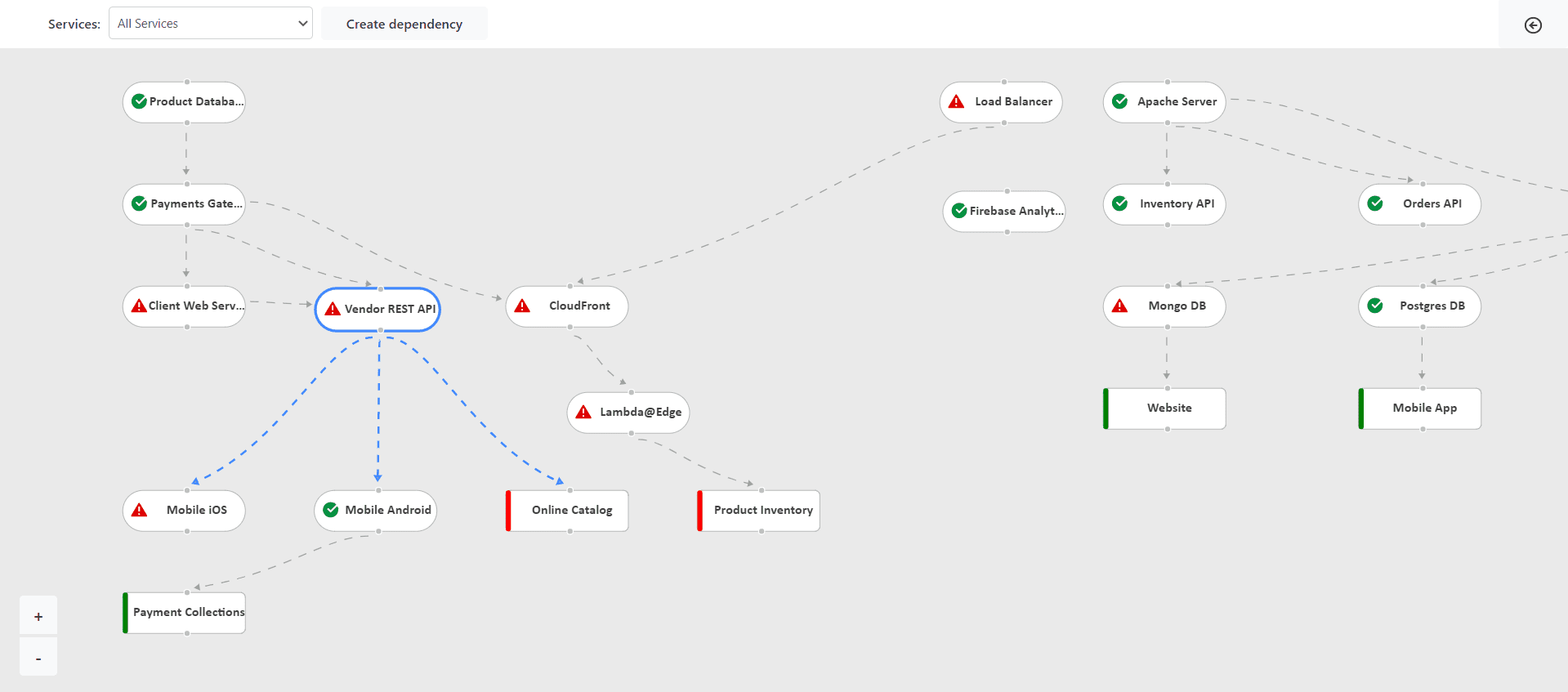
Handle incidents proactively so they never make it to your clients. TaskCall has a service based ownership structure that not only allows each team to take ownership of what they are responsible for, but also define how each service, including business services that are used by end clients, are dependent on each other. When an incident occurs on a service, TaskCall automatically identifies what other services and business services have been impacted by it and highlight them to the responder. The dependency graph makes it easy to see the trickledown effect of the impact so responders can analyze the full severity of the matter and prioritize fixes as needed.
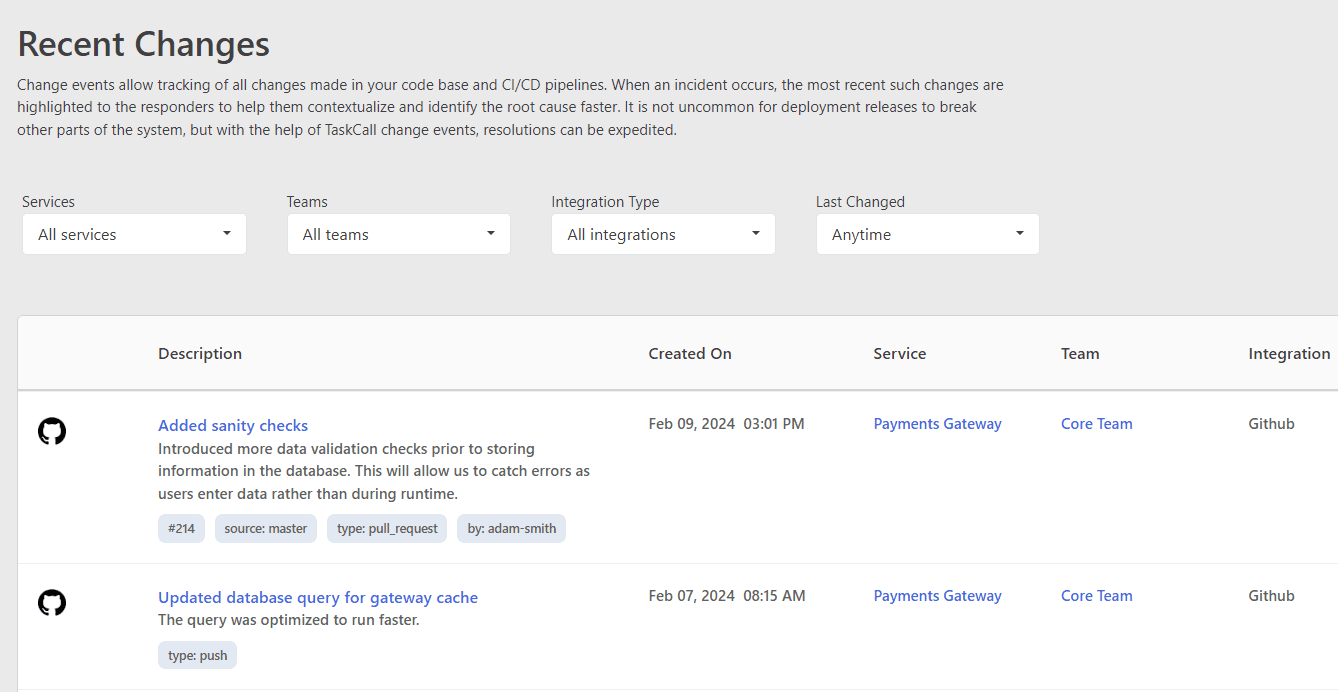
View Recent Code Changes with Incident Root Causes
Many incidents are a result of faulty code deployments or builds. TaskCall brings these changes to the attention of responders through built-in CI/CD pipeline integrations. Change events are labeled with helpful insights about time relevance and contextual similarity to the incident to make it easier for DevOps to catch on to important items. With better context, faster diagnosis and resolution are made possible.
Automate DevOps Diagnosis and Incident Resolution
When an incident occurs, TaskCall automatically identifies similar incidents that may have happened in the past to help DevOps engineers so they can learn what was done in the past. In other cases, through built-in integrations with Rundeck and other CI/CD tools, automated diagnostics can be run as soon as an incident occurs to identify the core problem and eliminate unnecessary possibilities. Resolutions can also be automatically executed through custom actions that connect with your system securely. For sophisticated solutions, incident workflows can be configured to run automatically to run a chain of actions conditioned on each other's outcomes. Let machines do the work where it can. Mitigate on-call fatigue and enhance response methodologies.