IT Crisis Management Guide: Best Practices for DevOps Teams

You can develop and deploy the most useful and advanced software, but if your technical team does not respond quickly during crisis times like system outages, deployment failures, security breaches, data loss or infrastructure failure, then all your efforts will go in vain.
When your system goes down in the middle of peak traffic time, or a critical service suddenly stops responding at 2 AM in the night, that’s when your DevOps team needs proper IT crisis management for rescue. How your team deals with it in the first few minutes will determine whether your site is recovering smoothly or leads to downtime or customer loss.
System failures are constant, but with a proper crisis management plan, your entire ecosystem can be saved. For reliable business operation, having a strong and automated IT crisis management process is inevitable.
If you recall the AWS outages in December 2021, that didn’t just cause severe outages of giant platforms like Netflix, Disney+, or even Amazon delivery service but also hampered business popularity on a global scale.
In this guide, we will learn how DevOps teams can build a proactive IT crisis management plan. Also, learn about the best practices of incident management for the DevOps team with a proper incident management software to respond quickly.
What is IT Crisis Management?
In simple words, crisis management is a set of well-planned, structured rules for preparing, handling, responding, and recovering from a sudden system failure or a critical software outage. Before heading to a detailed explanation, let’s quickly overview some types of IT crises DevOps mostly face-
System Outages: It happens when a specific application or service suddenly stops working. It leads to downtime of websites, apps, or internal tools for hours.
Cybersecurity Breaches: It involves stealing, exposing, or gaining access to sensitive data of your website and users. This kind of crisis mostly affects user trust and requires immediate legal reporting and security audits.
Deployment Failures: When developers release new code, it breaks the system instead of improving it. This mostly happens in CI/CD pipelines when a dev team can not detect the bug while testing.
Infrastructure Failure: Major servers crash, network downtime, or cloud downtime.
Data Loss or Corruption: When user data gets damaged, deleted, or inaccessible.
So, for every DevOps team, having an effective IT crisis management plan is mandatory to maintain minimal downtime, customer trust, and business continuity.
IT Crisis Management is a structured emergency plan for IT crises that we mentioned above. Crisis management is more than troubleshooting. It demands prevention strategies- automated failover and real-time monitoring, runbooks- documented response procedures, and post-crisis learning like blameless postmortems.
The goal of crisis management is to resolve and restore the specific service quickly while limiting damage and protecting both the business and its users.
An ideal crisis management tool offers:
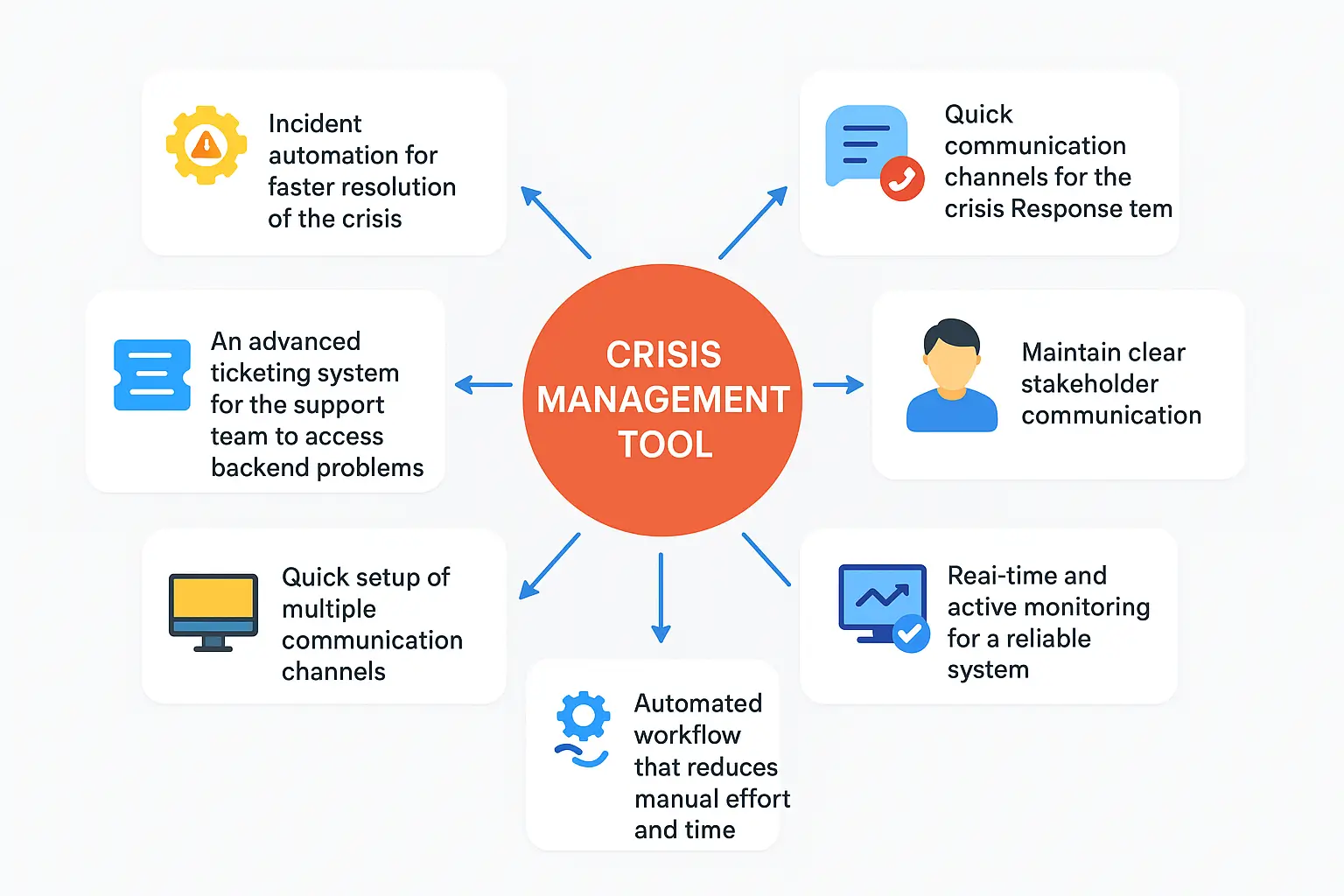
-
Incident automation for faster resolution of the crisis.
-
Quick communication channels for the crisis Response team
-
An advanced ticketing system for the support team to access backend problems
-
Maintain clear stakeholder communication
-
Quick setup of multiple communication channels.
-
Real-time and active monitoring for a reliable system.
-
Automated workflow that reduces manual effort and time.
Technical errors are a common phenomenon in the software industry. But some problems can bring your entire business to a halt. If a crisis is not handled correctly and quickly, the impact can go beyond website downtime. That’s why every DevOps team needs a proactive and clear crisis management plan to act quickly on incidents, collaborate smoothly, and restore service first.
7 Best Practices for Effective IT Crisis Management
Handling major incidents or outages isn’t just about fixing failures, it’s about how quickly your DevOps team responds and restores the whole service while protecting customer trust.
We will explore 7 best practices that will help DevOps teams develop a clear, strong, repeatable crisis response strategy that is effective in real-world environments.
Crisis Management Procedure
Things can go wrong in IT, and that’s a fact. The problem is what types of procedures the DevOps team is approaching to prevent the incident from becoming a full-blown crisis. Without a clear and defined IT crisis management plan, even a small incident can turn into a full-scale outage.
So, detailed procedures should be documented for every phase-
-
Crisis detection - real-time monitoring and alerting
-
Logging - utilize a crisis management software for automated crisis logging
-
Priority based crisis classification (P0 Critical - P4 Minimal)
-
Runbooks and playbooks for a smooth investigation
-
Define crisis response roles clearly - commander, automation lead, communication lead, subject matter expert, and documentation lead.
Establish On-Call Scheduling
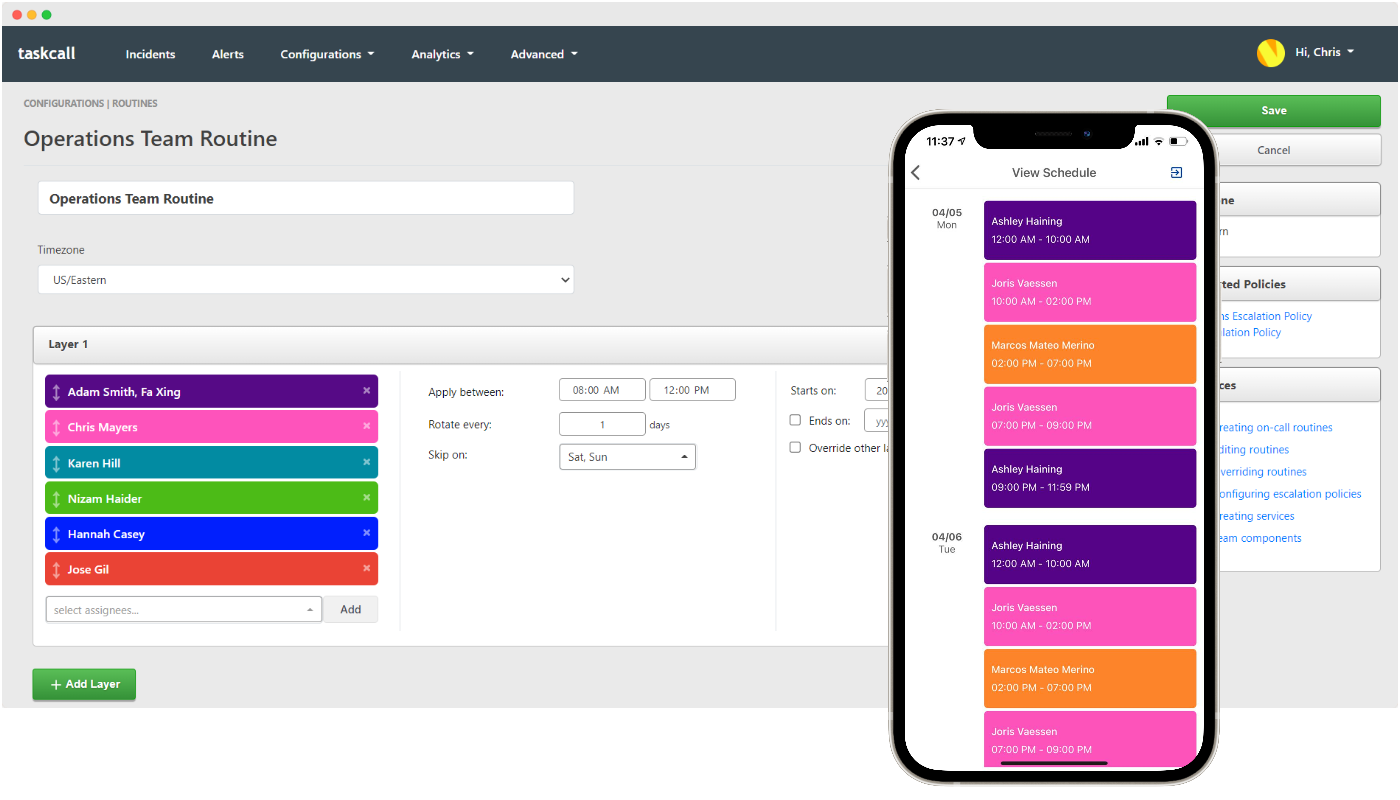
Setting up on-call rotation ensures that there is always someone available to address the incident quickly. A proper on-call scheduling is the first step of the incident response process.
A well-planned on-call scheduling allows dynamic and flexible rotation of on-call engineers. Dynamic scheduling determines when any crisis occurs, who needs to be alerted, and to be joined. It also helps to distribute responsibilities evenly so that any incident is never left unnoticed.
Automate Incident Workflows for DevOps Time Efficiency
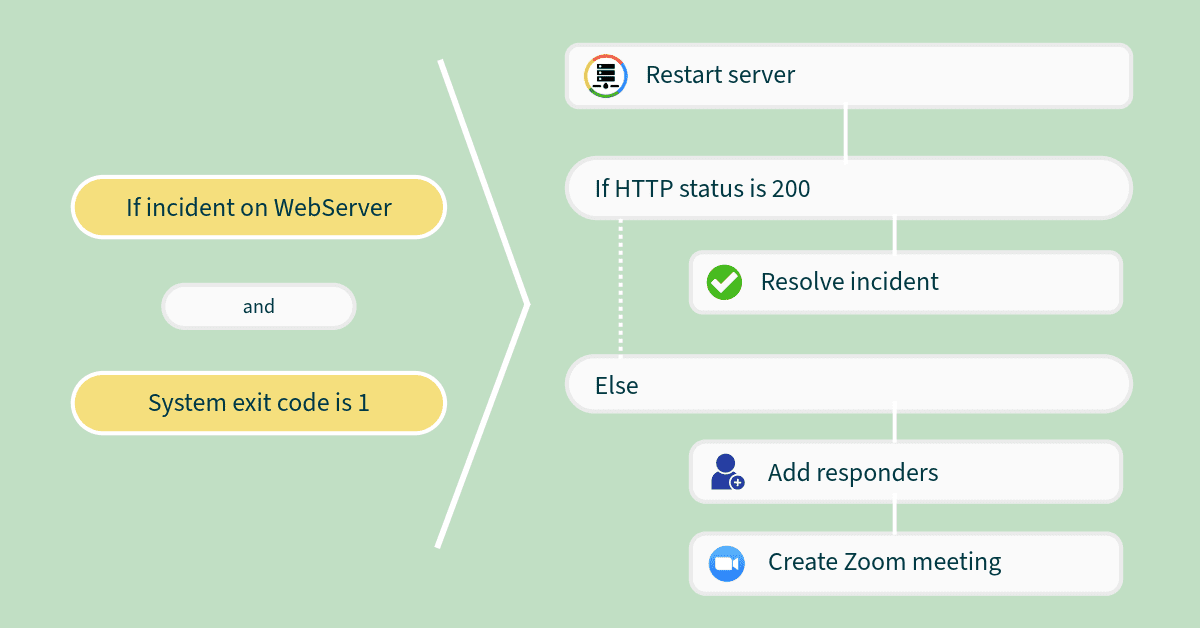
When a crisis happens, every second matters. Repetitive manual tasks like appointing responders, sending alerts, or gathering logs cost valuable time. Automated workflow through a chain of commands allows the team to focus on diagnosis and recovery. Hence, for modern crisis management software, incident workflow automation is an integral part to lessen the manual effort of the DevOps team.
Some highlighted automated incident workflows are-
Automatic incident alerts: When any crisis or incident happens, instead of manual detection by someone system like Taskcall, triggers alerts automatically. Taskcall has direct integration with Datadog and Sentry to push real-time notifications.
Real-time monitoring: Real-time monitoring of any incident gives technical teams a full visual representation, like- logs, graphs, and metrics, under one dashboard.
Automated escalation policy: This automated policy allows to set up multi-level support so that when any primary on-call responder misses any incident, it automatically escalates to the second responder. TaskCall leverages predefined escalation chains to automatically notify the backup responders.
Playbooks and runbooks: For repetitive incident manual response is a waste of time. Playbooks and runbooks execute pre-defined actions. Taskcall has integration with Rundeck for a runbook automation system.
Automated workflow not only enhances efficiency but also reduces human error, repetitive tasks, and MTTR (Mean Time to Recovery). It also ensures a consistent improvement while allocating more resources and time for innovation.
Maintain Runbooks and Playbooks for Efficient Crisis Handling
Documentation is vital during crisis management and post-incident analysis, also for future reference. Not every time the responder figures it out from scratch. Here comes runbooks and playbooks as saviours.
Runbooks are step-by-step procedures for known issues. You can define runbooks as technical instructions. Usually, runbooks include pre-defined commands, API restart commands, and verification tests.
On the other hand and playbooks act as operational strategies. Playbooks are more like crisis response strategies for a specific failure scenario, like a database failure. It defines operational plans that include a communication plan, response roles, escalation points, and communication updates.
Having these detailed guidelines always readable and updated ensures that on-call engineers can respond to issues on time without any disruption, even if they encounter a problem for the very first time.
Incident Communication Tools for Fast Collaboration With Stakeholders and Team
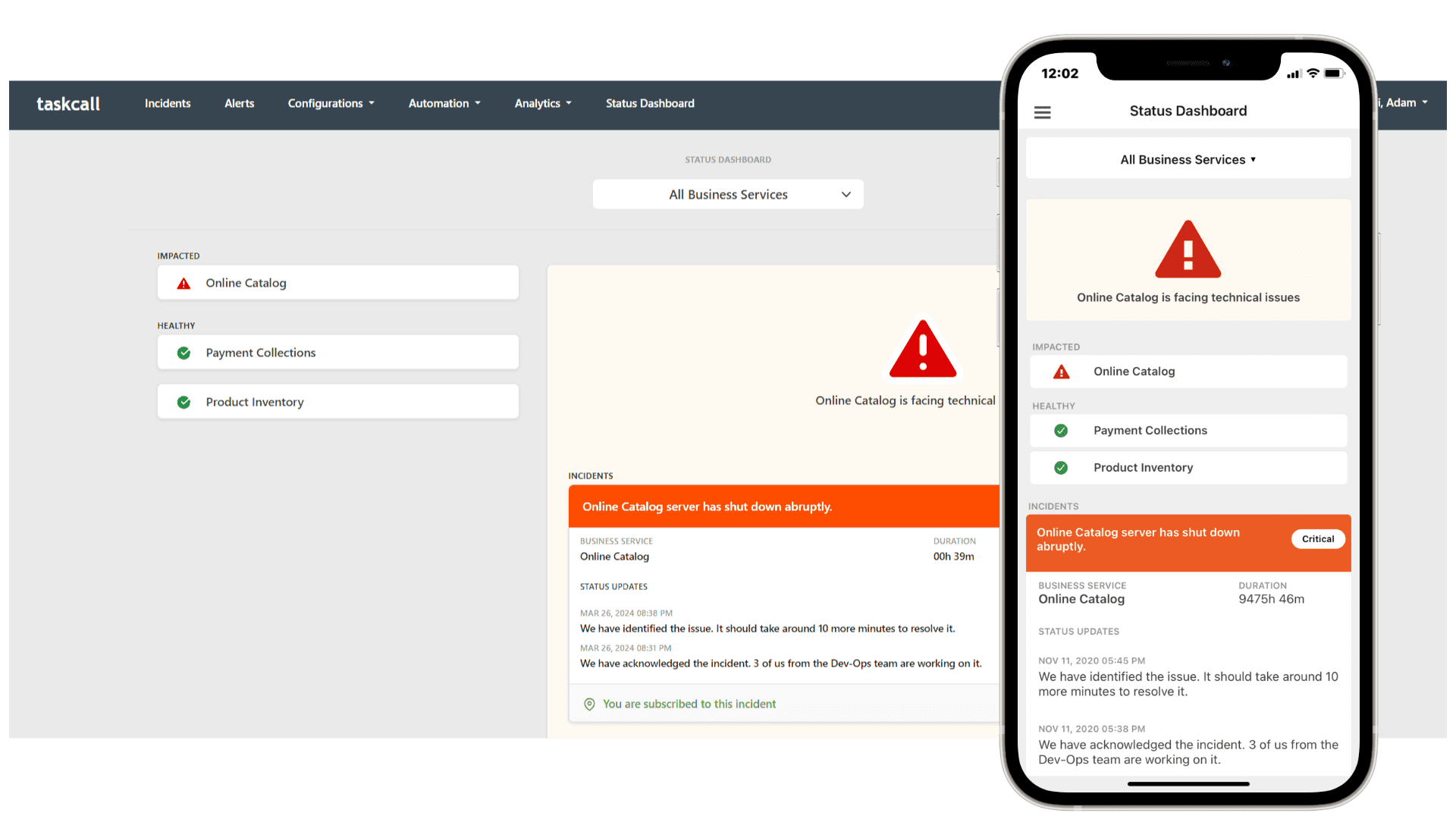
A quick setup of a crisis communication channel is necessary for further updates, logs under one unified space. It helps to maintain a proper recovery speed, show accuracy to the business stakeholders, and a clear visibility among all the team members.
Depending on disconnected tools such as Slack threads, randomly created WhatsApp groups, spreadsheets, or random series of emails are just a waste of time, which eventually increases MTTR.
To maintain clear and consistent stakeholder communication, there should be an internal status page where stakeholders can get updates in time from multiple teams like DevOps and support teams. The focus point of this status page is that responders will update on the crisis or incident they are handling, as well as the current update of the service that has been interrupted. This automated process lets stakeholders be updated about the incident without directly communicating with the team.
Establishing A Blameless Culture for Post-Analysis
A blameless culture is essential to focus on sharing everyone’s information for a reliable system, rather than engaging in unnecessary finger-pointing.
Incorporating a blameless culture encourages open discussion and a consistent learning system. This approach makes team members feel safe and gives freedom to talk about how they handle the incident and resolve this. Another point is root cause analysis, which includes analyzing metrics like CI/CD history, latency, or deployment logs.
This culture only works when it leads to actionable learning. After every major crisis, teams should conduct a Post-Incident Review (PIR) to address specific tasks, including strengthening rollback scripts, adding alert rules, fixing broken runbooks, or improving automated workflows.
Incorporating Chaos Engineering to Test Failure Scenario
This is a proactive reliability approach where failure in the system is intentionally injected to examine its resilience, as well as how it handles real-time outage conditions.
Teams can simulate different failure scenarios like network latency, server crashes or dependency time-out. By implementing regular chaos experiments, the DevOps team can reveal performance bottlenecks and hidden system dependencies.
The ideal way to implement chaos engineering into a crisis management system is by combining it with automation, structured runbooks, and post-incident learning. Moreover, these types of testing should start in a staging environment (Pre-Production) so that real users don't get affected, and teams need an immediate safe rollback plan to restore the system.
TaskCall for IT Incident Management Solution
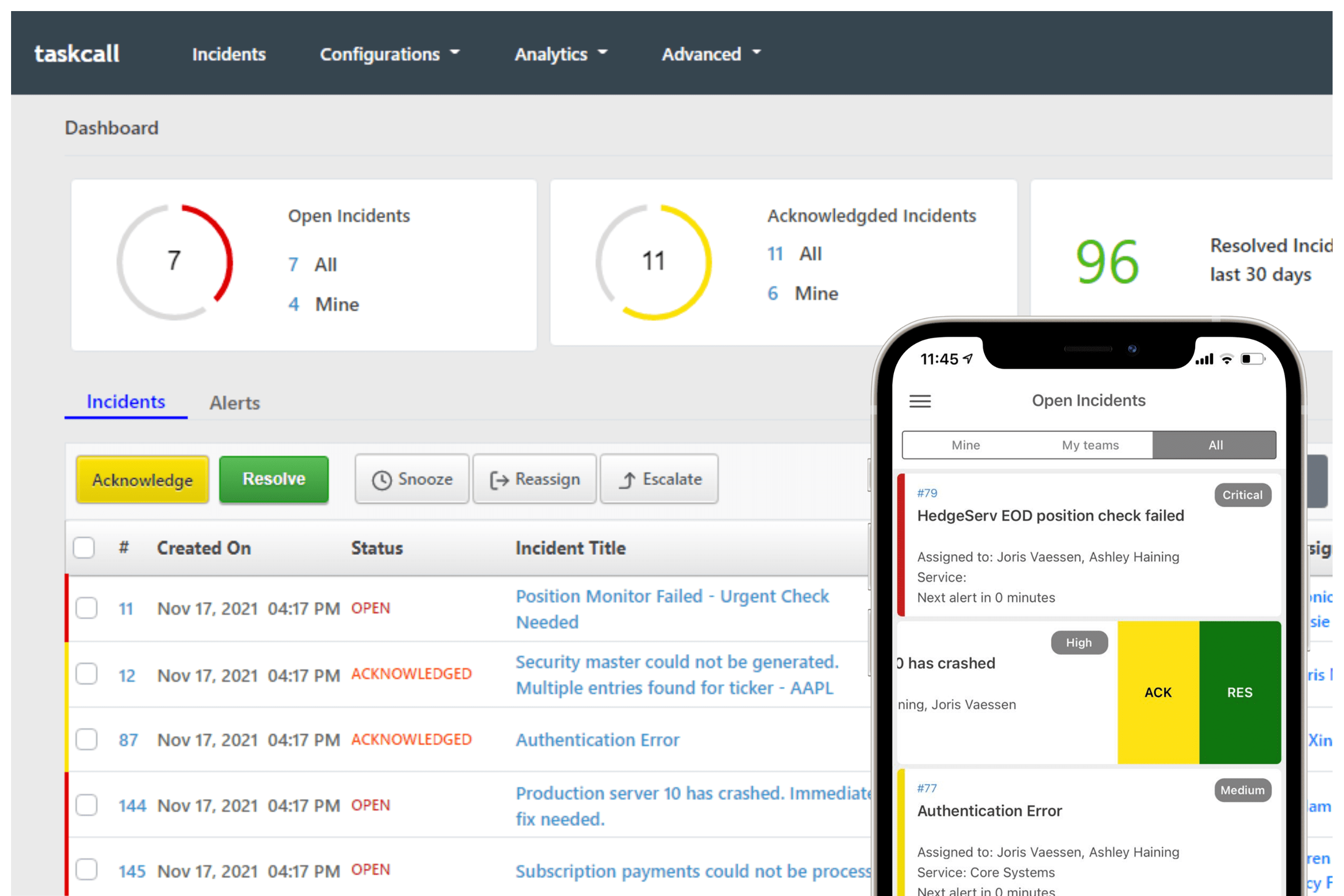
An ideal crisis management software is all about fast crisis detection, automated incident response and impactful post-analysis with continuous learning. Taskcall is designed for the DevOps team to solve common problems that slow down incident response.
It provides a unified communication for teams, replaces manual coordination with automated tasks, and most importantly, the incident reaches to the right person in time. Taskcall is more than an alert software that helps DevOps and IT teams to identify, respond, and resolve crises quickly for minimal downtime and protect brand reputation.
Its features, such as automated workflows, real-time collaboration with team and stakeholders, intelligent alert routing, on-call management and automated escalation policies, ensure a smooth business operation regardless of any crisis.
TaskCall allows tech teams to respond faster, recover smarter with automation and prevent further burnout using post-incident analysis, making it an ideal choice for enterprise-level incident management. Try now for 14-day free trial.
Frequently Asked Questions
What is an IT crisis management system?
An IT Crisis Management System is a well-structured and centralized platform that helps technical teams to quickly detect, respond, and recover from any critical incidents like outages, security breaches, or deployment failures.
How can DevOps teams decrease MTTR during crisis time?
To reduce Mean Time to Recovery (MTTR), teams can incorporate using on-call escalation policies, live call routing, automated alerting, runbook-based remediation, and real-time incident communication tools like TaskCall for easy team coordination and in-time response.
Why do crisis management systems matter for DevOps teams?
Crisis management systems are necessary to prevent unnecessary system downtime, customer dissatisfaction, revenue loss, and mostly to stay coordinated and respond faster.
What are the key features to look for in an IT crisis management tool?
While researching an ideal crisis management tool, look for features like dynamic live call routing, on-call scheduling, automated escalation policies, real-time collaboration channels, and post-incident reporting.
How does TaskCall support IT crisis management at the enterprise level?
TaskCall can be your ideal crisis management tool by providing on-call scheduling, real-time alerting, automated on-call escalation and stakeholder notifications.
You may also like...
Incident response is the process of addressing technical issues that occur in a company. It could be business application errors, database issues, untested deployment releases, maintenance issues or cyber-security attacks. Automation allows such incidents to be resolved fast and save losses.
One of the core pieces of maintaining a sophisticated operation is delegation of responsibilities. If one individual ends up doing bulk of the work then the whole process will be slowed down. Their individual efficiency will not hold up to the standard either.