Enterprise Incident Management for Large-Scale IT Operations

Imagine your company’s website goes down during peak business hours. Customers cannot place orders, employees scramble for answers and every passing minute feels like an eternity. For enterprises managing large digital infrastructures, this situation poses a direct threat to revenue, reputation and customer trust. That’s why enterprise incident management has become a crucial priority for modern IT operations.
Enterprise Incident Management (EIM) offers a structured approach to detect and resolve issues before they turn into costly disruptions. Unlike basic troubleshooting, EIM addresses the complexities of enterprise environments, where multiple teams, global operations and compliance demands intersect.
This guide will help enterprise teams understand the foundations of enterprise incident management, explore its best practices and evaluate the best incident management software for enterprise IT operations.
What is Enterprise Incident Management?
Enterprise Incident Management (EIM) is the structured process of detecting, responding to and resolving IT incidents across large and complex environments. Unlike ad-hoc or small-scale incident handling, EIM is designed to support enterprise IT operations where the stakes are higher and downtime can have a significant financial and reputational impact. Adopting frameworks like the ITIL incident lifecycle helps enterprises standardize incident logging, categorization, escalation and resolution for quicker recovery and improved service reliability.
The difference between basic incident management and enterprise-level approaches is primarily in scale, automation and governance. Smaller organizations often use manual processes, while enterprises need automated escalations, dynamic on-call scheduling, compliance reporting and real-time collaboration. Without a structured strategy, large organizations experience longer resolution times, higher costs and greater service delivery risks. Thus, Enterprise Incident Management is crucial for building resilient operations that can quickly adapt to disruptions.
Why Enterprise Incident Management Matters for Large-Scale IT Operations
High Cost of Downtime
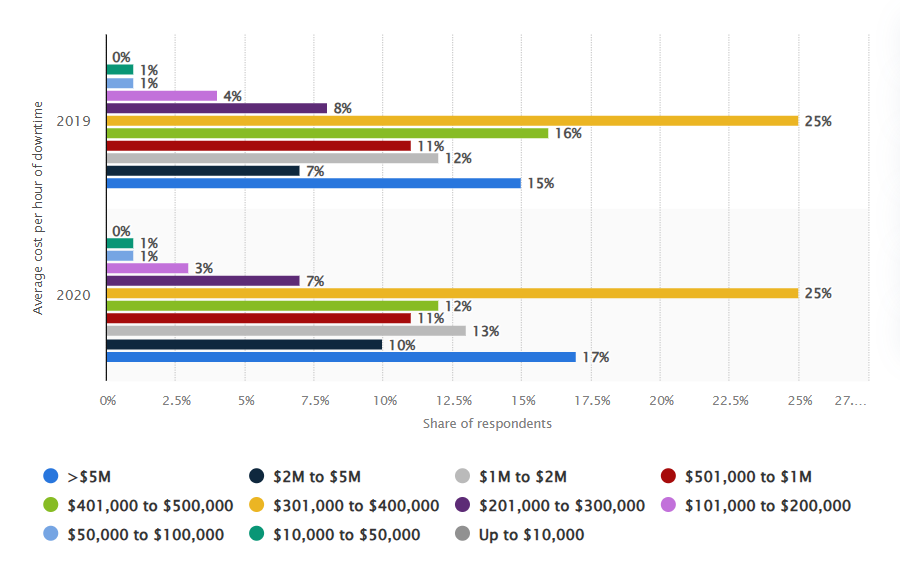
Source: Statista
Downtime is one of the most expensive risks enterprises face. According to a Statista survey, 25% of global enterprises reported that the average hourly cost of critical server outages ranged between $301,000 and $400,000. For many organizations, even a short disruption can quickly escalate to significant financial losses.
The impact of downtime extends beyond direct revenue loss. Customer-facing industries, such as e-commerce, banking and telecom, risk damaging brand reputation and customer trust with every minute of unavailability. Regulatory-heavy sectors like healthcare and finance face an added burden, as downtime may trigger compliance violations or data security concerns.
Complexity of Multi-Team Collaboration
Large enterprises often have IT operations spread across multiple regions and time zones. This makes incident collaboration challenging, especially when different teams use different communication tools. Delays in coordination often result in slower resolution times and duplication of effort.
Compliance, Security and Customer Trust
Enterprises in regulated industries such as financial services, healthcare and telecommunications face strict compliance requirements. Failure to meet SLA commitments or maintain proper audit logs can result in heavy fines, legal penalties and loss of customer trust. Maintaining transparency and accountability during incident management is therefore essential.
Core Components of Incident Management for Enterprise
Effective incident management for an enterprise relies on several key components that work together to ensure timely detection, efficient response and continuous improvement. These components form the backbone of a resilient IT operation, enabling enterprises to minimize downtime and maintain service reliability.
Incident Detection and Alerting
Timely detection is essential for a successful incident response strategy. Enterprises must integrate advanced application performance monitoring tools like Datadog, AWS CloudWatch and AppDynamics to identify anomalies and potential issues before they escalate into major incidents. These tools provide real-time insights into system performance, helping organizations detect irregularities early.
However, detection alone is not enough. Enterprises must consolidate alerts from multiple monitoring systems into a unified platform to avoid the chaos of scattered notifications. This centralization reduces the risk of alert fatigue, where teams become overwhelmed by excessive notifications and miss critical issues. Intelligent filtering further enhances this process by separating high-priority alerts from less urgent ones, ensuring that teams focus their attention on the most critical incidents. By streamlining detection and alerting, enterprises can significantly reduce response times and improve overall efficiency.
Automated Escalations and On-Call Management
In large-scale IT operations, ensuring 24/7 availability requires a structured approach to on-call management and escalation. Enterprises must establish dynamic on-call schedules and escalation policies to guarantee that the right team members are always available to address incidents. Rotating on-call responsibilities among team members not only ensures fair workload distribution but also prevents burnout.
Redundancy is another critical aspect of on-call management. By building redundancy into escalation policies, enterprises can ensure that no alert goes unanswered, even if the primary responder is unavailable. Automated escalations play a vital role here, as they eliminate delays by instantly routing unresolved incidents to the next available team member. This structured approach to on-call management ensures that critical services remain protected around the clock, minimizing the risk of prolonged downtime.
Incident Workflow Automation
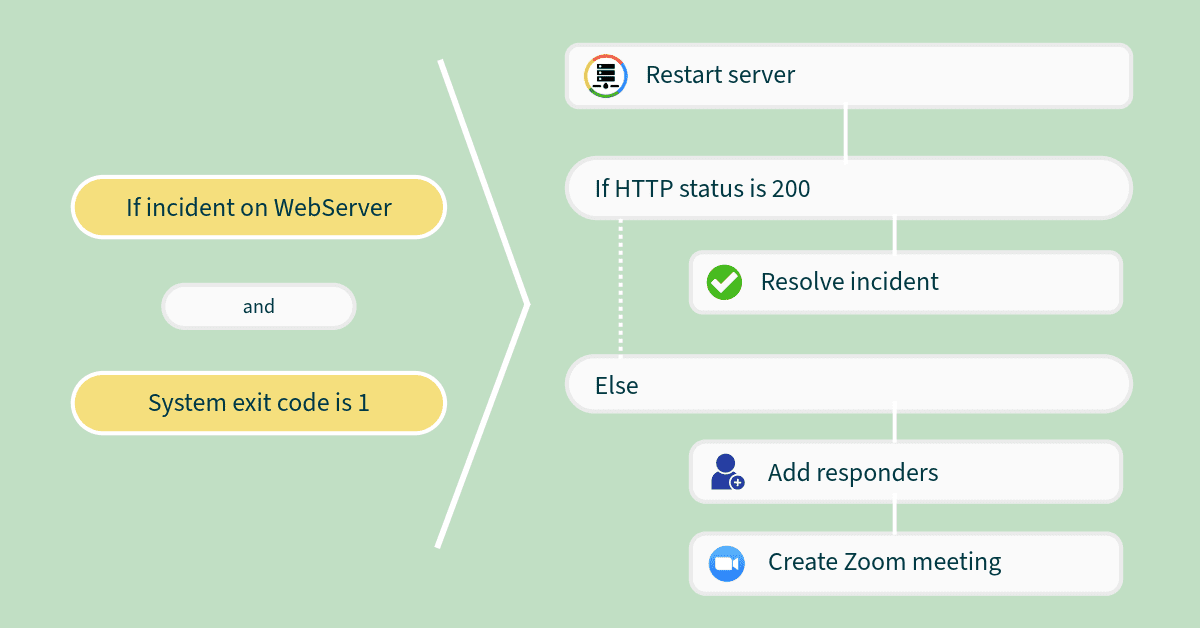
Incident Workflow Automation is a game-changer in enterprise incident management, eliminating delays and reducing the manual workload during high-pressure situations. Predefined workflows can be programmed to handle repetitive tasks such as restarting servers, clearing caches or running diagnostic scripts. These automated actions not only save time but also reduce the risk of human error, which can exacerbate incidents.
By integrating automation with IT Service Management (ITSM) platforms, enterprises can maintain consistency in incident tracking and resolution. For example, automated workflows can create, update and close tickets in ITSM systems, ensuring that all incidents are properly documented. Additionally, predefined playbooks provide teams with step-by-step guidance for handling specific types of incidents, further accelerating response times. With workflow automation, enterprises can resolve incidents faster and allocate resources more efficiently.
Real-Time Team Collaboration
Effective communication is essential when multiple teams are involved in incident response. Enterprises must establish centralized "war rooms" where all stakeholders can collaborate in real time. These war rooms serve as a single source of truth, ensuring that everyone is aligned on the status of the incident and the steps being taken to resolve it.
Integrations with popular collaboration tools like Google Chat, Microsoft Teams, Zoom and Webex further enhance communication by enabling seamless interactions across distributed teams. These tools allow technical and non-technical stakeholders alike to stay informed with real-time updates, fostering transparency and trust. By prioritizing real-time collaboration, enterprises can reduce confusion, improve decision-making and accelerate incident resolution.
Post-Incident Analysis and Continuous Improvement
Every incident is an opportunity to learn and improve. Enterprises must conduct thorough post-incident analyses to identify the root causes of issues and implement measures to prevent recurrence. This process begins with generating audit-ready logs and reports that provide a detailed account of the incident, including the actions taken and their outcomes. These logs are essential for compliance, especially in regulated industries.
Tracking performance metrics such as Mean Time to Resolution (MTTR) and Mean Time to Detect (MTTD) is another critical aspect of post-incident analysis. These metrics help organizations evaluate the effectiveness of their incident response processes and identify areas for improvement. Regular post-incident reviews provide teams with actionable insights, enabling them to refine workflows, update playbooks, and enhance automation. By fostering a culture of continuous improvement, enterprises can build more resilient IT operations that are better equipped to handle future challenges.
Best Practices for Enterprise Incident Management
To ensure seamless operations and minimize downtime, enterprises must adopt proven strategies for effective incident management. These best practices help organizations streamline their processes, improve collaboration and enhance overall service reliability.
Centralize Incident Alerts for Better Focus
Managing incidents across multiple dashboards can create silos and increase the risk of missed alerts. By consolidating all monitoring tools into a unified platform, enterprises can ensure that teams receive the right information at the right time. Intelligent filtering further reduces alert fatigue by prioritizing critical notifications, allowing responders to focus on actionable issues.
Define Clear Escalation Policies
Without well-defined escalation rules, critical incidents may go unnoticed or unresolved for too long. Establishing clear escalation policies ensures accountability and guarantees that urgent issues are addressed promptly. Mapping escalation paths across global teams and time zones ensures 24/7 coverage, minimizing delays in response.
Leverage Automation to Accelerate Resolution
Manual incident response processes can slow down resolution times and increase the risk of errors. Automating repetitive tasks, such as restarting servers or running diagnostics, helps reduce Mean Time to Resolution (MTTR). Integrating automation with ITSM platforms ensures consistent incident tracking and faster recovery.
Prioritize Real-Time Team Communication
Real-time team communication is essential for effective incident management, particularly in large-scale enterprise settings. Delays in communication can lead to confusion, slower resolutions, and misaligned efforts. Tools like Slack, Microsoft Teams and Zoom enable instant collaboration among stakeholders, while centralized war rooms provide a single source of truth for updates and decisions. This ensures that technical teams, business leaders, and non-technical stakeholders stay aligned throughout the incident. Transparent communication not only accelerates decision-making but also builds trust, minimizing the overall impact of disruptions.
Conduct Post-Incident Reviews for Continuous Improvement
Post-incident reviews are vital for identifying lessons and improving processes. By analyzing what went wrong and tracking metrics like Mean Time to Resolution (MTTR) and Mean Time to Detect (MTTD), enterprises can uncover root causes and refine their workflows. These reviews should include actionable steps to update playbooks, enhance automation and prevent repeat issues. Sharing insights across teams fosters a culture of continuous improvement, strengthening incident response capabilities and ensuring long-term operational excellence.
By implementing these best practices, enterprises can build a resilient incident management strategy that minimizes downtime, enhances collaboration and ensures compliance with regulatory standards.
How TaskCall Supports Enterprise Incident Management
TaskCall is designed to be one of the top enterprise incident management software solutions for large-scale IT operations. It helps large-scale IT operations respond faster, collaborate effectively, ensure compliance and continuously improve incident response. Here’s how TaskCall supports every stage of enterprise incident management;
Reduce Downtime with Faster Response
Downtime is one of the biggest threats to enterprise IT operations, with even a few minutes resulting in substantial financial and reputational damage. TaskCall helps minimize downtime by delivering real-time alerts, incident response and escalations that ensure incidents are routed instantly to the right teams. By reducing response delays, enterprises can lower MTTR, restoring services faster and keeping critical business operations running smoothly.
Intelligent Alert Routing Across Multiple Teams
In complex enterprise environments, sending alerts to the wrong team can delay resolution and increase downtime. TaskCall’s intelligent alert routing ensures that every incident is automatically assigned to the right team or individual, reducing Mean Time to Resolution (MTTR). By prioritizing critical alerts and filtering out noise, TaskCall keeps teams focused on what matters most.
Improve Collaboration Across Teams and Time Zones
Enterprises often operate across multiple regions, departments and time zones, which can complicate coordination during incidents. TaskCall enhances collaboration by offering multi-channel integrations with a centralized incident war room. This ensures all stakeholders, from IT engineers to business leaders, stay aligned with real-time updates, enabling faster decision-making no matter where teams are located.
Save Downtime Costs with Automation and Streamlined Operations
Manual processes and inefficient workflows increase both operational costs and resolution times. TaskCall reduces these inefficiencies with workflow automation that handles repetitive tasks like restarting services, running automated diagnostics or triggering playbooks. By eliminating human error and reducing manual workload, TaskCall not only speeds up recovery but also allows enterprises to optimize resources and significantly lower operating costs.
Ensure Compliance and Strengthen Security
Compliance and security are non-negotiable for enterprises in industries like finance, retail and industrial plants. TaskCall supports compliance with audit-ready logs, SLA and role-based access controls. Every action during an incident is recorded, providing enterprises with the visibility and documentation needed to satisfy regulatory requirements and strengthen customer trust.
Real-World Example: A Global E-Commerce Platform Outage
Imagine a global e-commerce enterprise facing an unexpected outage during peak shopping hours. In a traditional setup, alerts might be delayed, escalations mishandled and communication fragmented, leading to hours of downtime and millions in lost revenue.
TaskCall streamlines the process by providing real-time alerts that trigger escalations to the appropriate on-call engineers. Automated workflows conduct diagnostics and implement quick fixes. At the same time, a centralized incident war room keeps IT, customer support and business leaders aligned on progress. As a result, the outage is resolved in minutes instead of hours, customer impact is minimized and the enterprise avoids costly revenue losses.
Final Thoughts on Incident Management for Enterprise
For large-scale IT operations, Enterprise Incident Management is no longer optional; it is a business-critical function. Structured incident response ensures faster resolution, better collaboration across distributed teams and stronger compliance with regulatory standards. Enterprises that invest in EIM strategies not only protect revenue and customer trust but also build long-term resilience.
TaskCall is specifically designed to help enterprises succeed in this field. By reducing downtime through real-time alerts and escalations, improving collaboration with multi-channel integrations and cutting costs with workflow automation, TaskCall gives organizations everything they need to manage incidents at scale with confidence.
Do not let downtime drain your enterprise. TaskCall empowers large-scale IT operations to stay resilient, collaborative and cost-efficient. Try TaskCall today and experience enterprise-grade incident management built for scale.
FAQs on Incident Management Software for Enterprise Organizations
What is enterprise incident management?
Enterprise Incident Management (EIM) is a structured process for detecting, responding to and resolving IT incidents in large organizations to reduce downtime and ensure reliable services.
Why is incident management important for enterprises?
It helps prevent revenue loss, service disruptions and compliance risks by enabling faster incident response and better team coordination.
What is the enterprise incident management process?
The enterprise incident management process is a structured workflow that enterprises use to detect, classify, respond to, and resolve IT incidents at scale. It ensures that critical issues are addressed quickly, downtime is minimized, and compliance requirements are met.
What is an enterprise incident management system?
An enterprise incident management system is a platform that helps large organizations detect, manage, and resolve IT incidents across complex infrastructures. It centralizes alerts, automates escalations, enables real-time collaboration, and provides audit-ready reports. These systems are designed to handle high volumes of incidents, support distributed teams, and ensure compliance with standards like SOC 2, HIPAA, and GDPR.
What is the best incident management software for enterprise?
TaskCall is one of the best incident management software for enterprises. It offers real-time alerts, automated escalations, workflow automation, dynamic on-call management and multi-team collaboration to reduce downtime and improve operational efficiency.
Why is TaskCall a top incident management tool for enterprises?
TaskCall offers automated incident response and management, real-time team collaboration, dynamic on-call management, automated escalations and integrates monitoring tools, making it ideal for enterprises.
How do enterprises choose the best incident management software?
Enterprises should prioritize tools with monitoring integrations, automation, global collaboration, compliance support and scalability. TaskCall meets these requirements, enabling faster response times, improved coordination and cost-efficient incident management at large scale.
Why do enterprises need specialized incident management software?
Large organizations have complex IT systems, multiple teams and strict compliance needs. Specialized software like TaskCall ensures faster incident resolution, reduced downtime, better collaboration and regulatory compliance, which generic tools cannot provide efficiently.
How can enterprises reduce downtime during incidents?
Use real-time alerts, automated escalations and workflow automation to quickly resolve incidents and keep services running.
Is TaskCall a better option than PagerDuty for enterprises?
Yes. TaskCall delivers enterprise-grade reliability, automation and collaboration features similar to PagerDuty but at 50% lower cost, making it ideal for organizations seeking scalable and cost-efficient incident management.
You may also like...
Incident response is the process of addressing technical issues that occur in a company. It could be business application errors, database issues, untested deployment releases, maintenance issues or cyber-security attacks. Automation allows such incidents to be resolved fast and save losses.
One of the core pieces of maintaining a sophisticated operation is delegation of responsibilities. If one individual ends up doing bulk of the work then the whole process will be slowed down. Their individual efficiency will not hold up to the standard either.