AI Incident Cause and Resolution: The Feature Opsgenie Never Built
When a P1 incident fires at 2 AM, the most expensive minutes in the entire incident lifecycle are the ones spent diagnosing root cause. An on-call engineer woken from sleep, navigating dashboards and log streams across multiple tools, manually correlating signals from a dozen different monitoring integrations - this is where mean time to resolution explodes, SLA windows close, and on-call burnout compounds over time. Opsgenie, throughout its entire product lifecycle, never addressed this problem with AI-driven analysis. Alert routing was its core competency, and it stopped there.
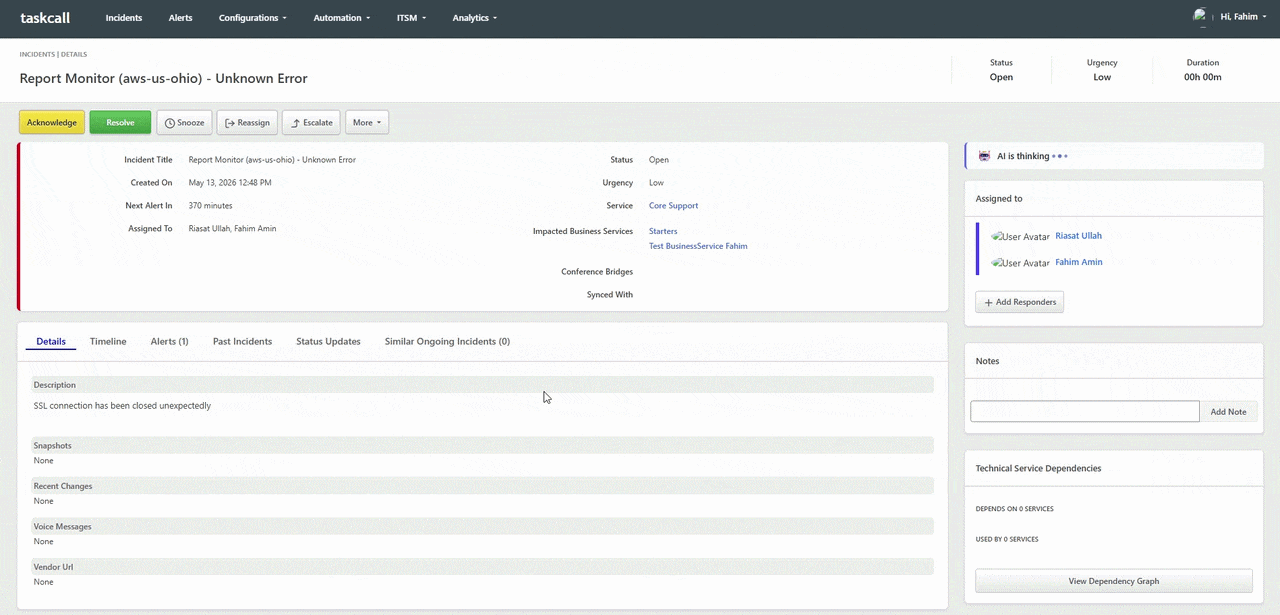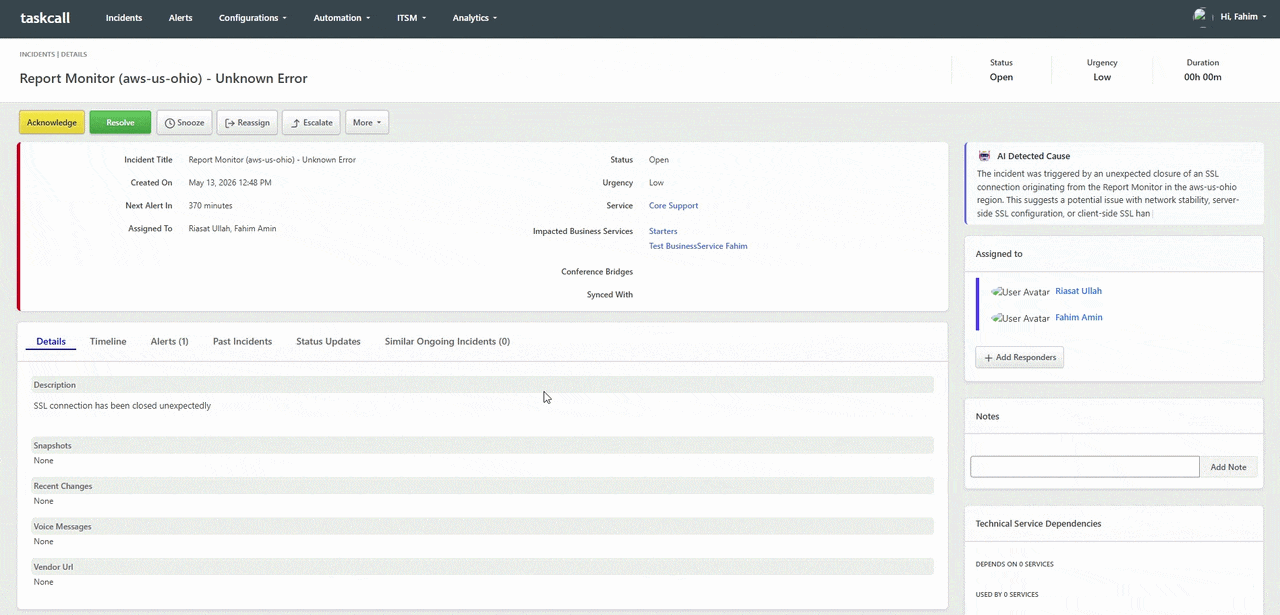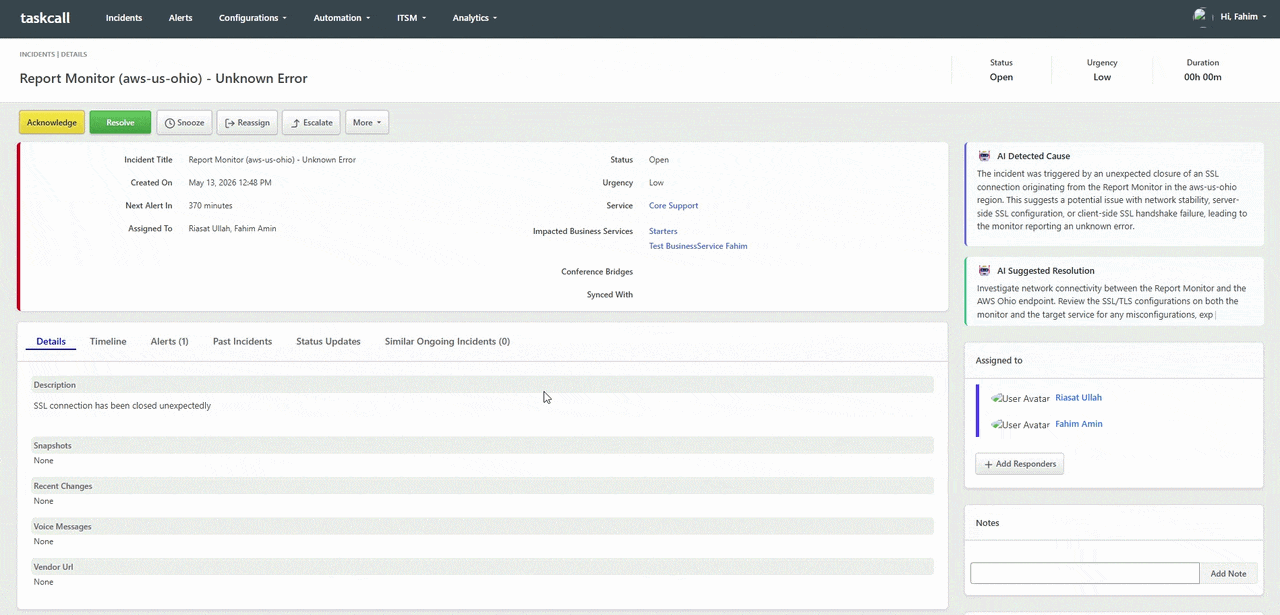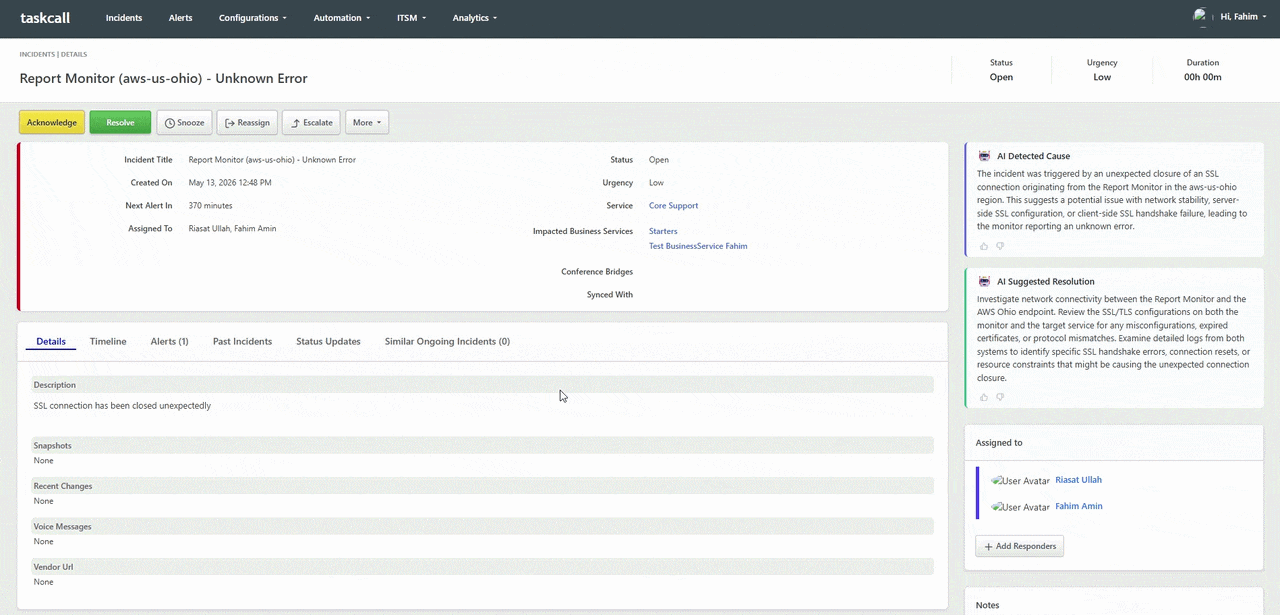
TaskCall's AI incident cause and resolution engine changes the calculus of the first five minutes of every incident. The moment a new incident is created, TaskCall analyzes the triggering alert, cross-references it against historical incident patterns, examines correlated signals from connected integrations, and surfaces a ranked list of probable root causes alongside recommended resolution steps. Engineers do not start from zero. They start with a hypothesis - one generated from the same data they would eventually reach manually, delivered instantly. For engineering teams managing complex distributed systems with dozens of interdependent services, this AI-powered diagnostic layer can mean the difference between a five-minute fix and a forty-minute war room.
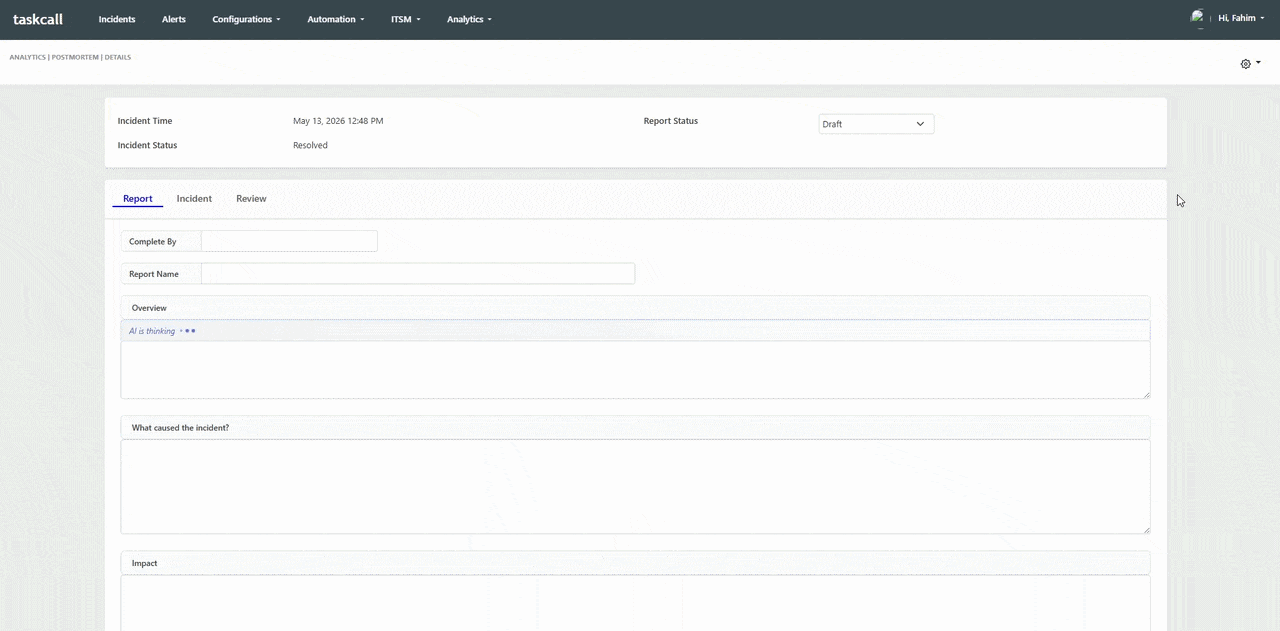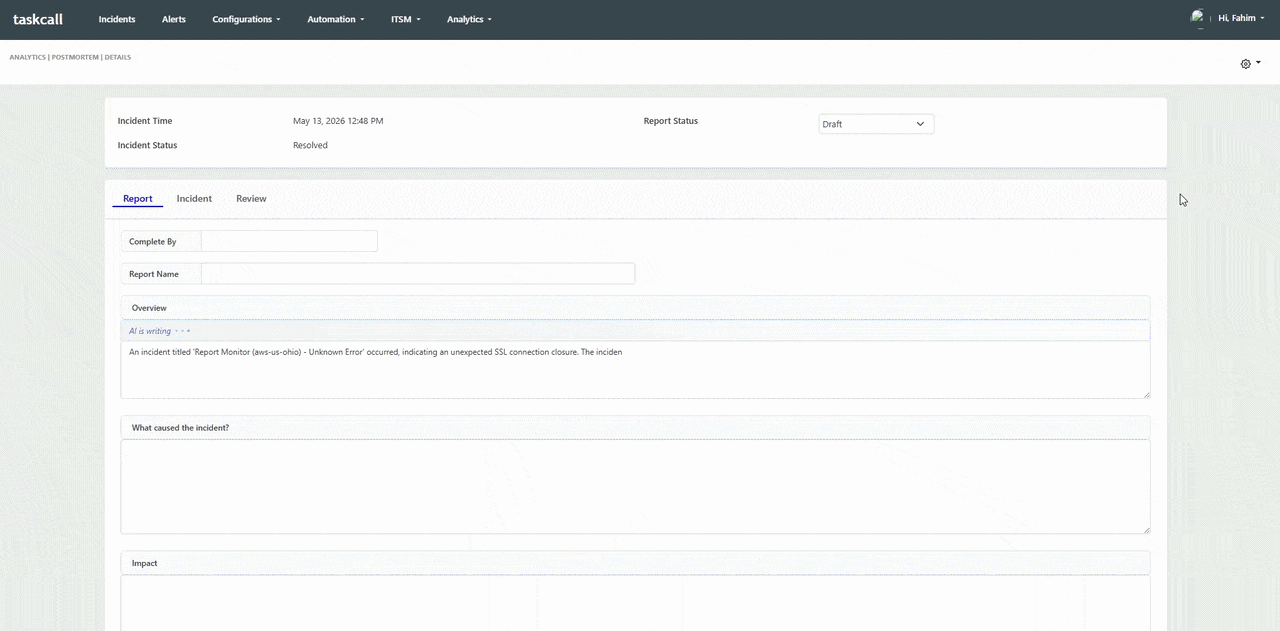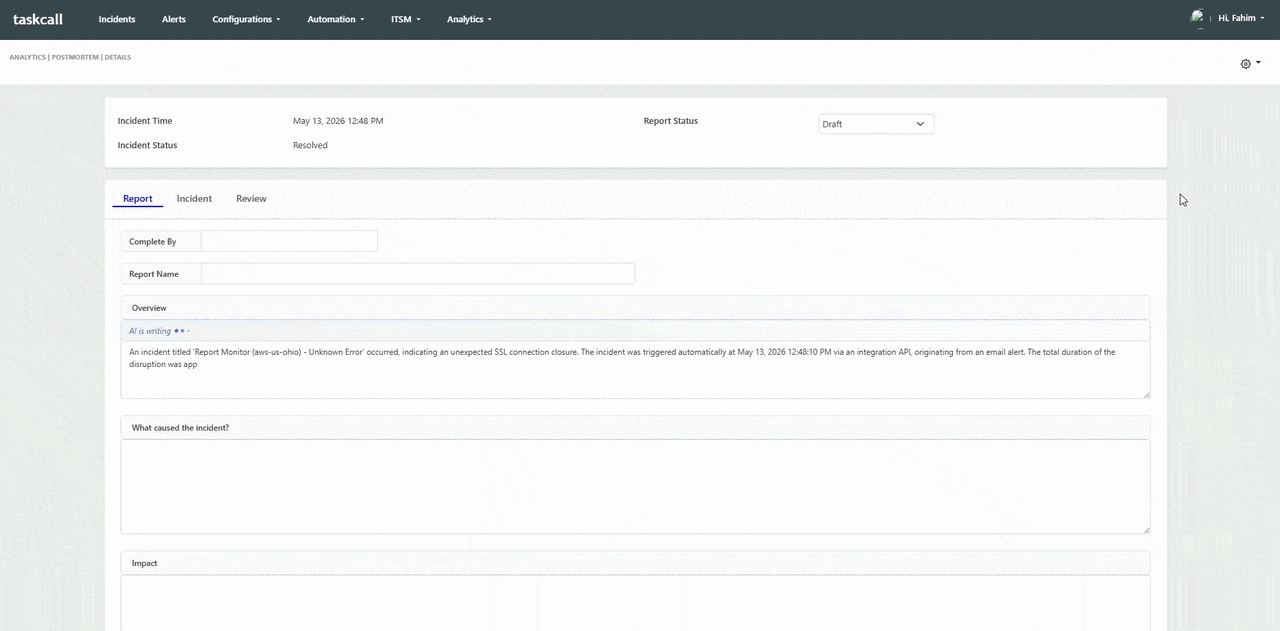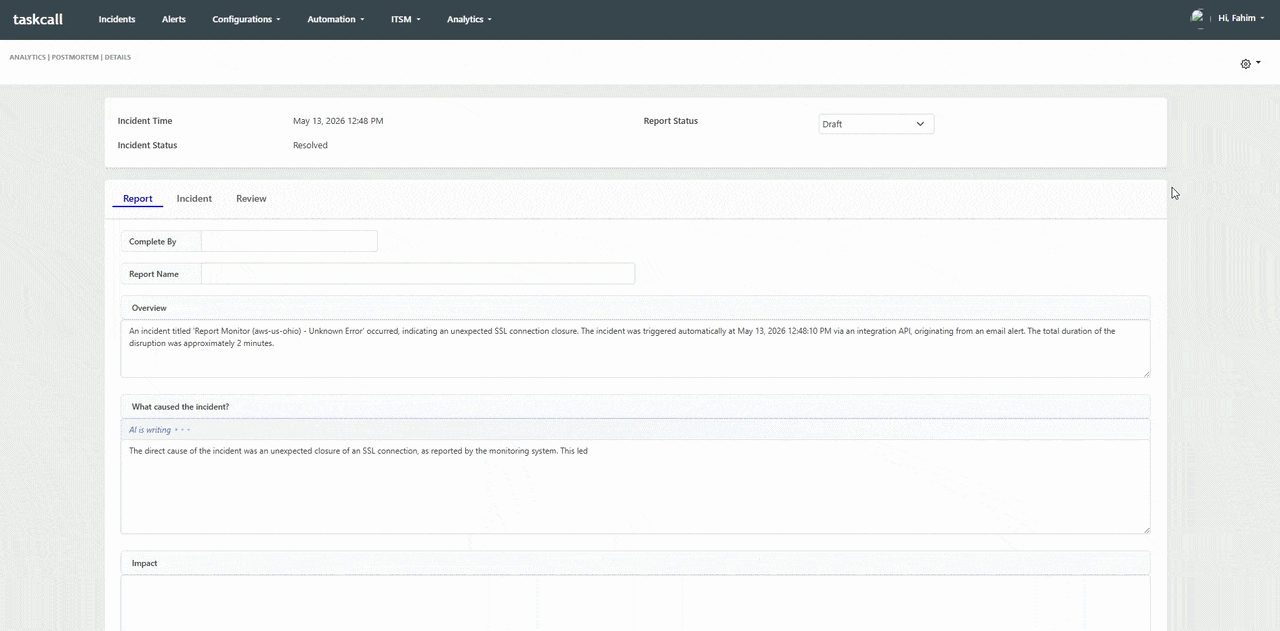
AI Postmortems: From Resolved Incident to Published Report in Minutes
Postmortems are essential to the reliability engineering practice, but they are consistently one of the most time-consuming artifacts that engineering teams produce. A complete, high-quality postmortem requires reconstructing a precise incident timeline, documenting every response action taken, analyzing contributing causes, and producing actionable follow-up items - all while the team is still recovering from the incident itself. In practice, postmortems get delayed, abbreviated, or skipped entirely because the manual effort required is simply too high given the other demands on an engineering team's time.
TaskCall's AI postmortem generation eliminates the blank-page problem. When an incident is resolved, TaskCall automatically compiles the complete incident timeline - including alert trigger times, acknowledgement records, escalation events, responder actions, and resolution notes - and generates a structured postmortem draft that meets standard blameless postmortem format requirements. Teams review, annotate, and refine the AI-generated draft rather than building it from scratch. The result is a higher rate of postmortem completion, more consistent documentation quality, and faster time-to-publish for the reports that drive long-term reliability improvements. Opsgenie offered basic postmortem support but no AI generation capability, leaving the most labor-intensive part of the process entirely manual.
Intelligent Noise Reduction: Fewer Pages, More Signal
Alert fatigue is one of the defining challenges of modern on-call operations. A single degraded microservice can trigger hundreds of downstream alerts within minutes. A misconfigured threshold can generate thousands of notifications per day for a condition that resolves itself without human intervention. Over time, the accumulated cognitive load of high-volume, low-signal alerting erodes the reliability of the entire on-call function: engineers stop responding to notifications with urgency, critical incidents get missed in the noise, and on-call rotations become a source of chronic burnout rather than a resilient operational safeguard. Opsgenie had no intelligent noise reduction capability to address this problem - alert correlation and suppression were entirely absent from its feature set.
TaskCall's intelligent noise reduction engine operates continuously across all incoming alert traffic. It uses signal fingerprinting to group related alerts from the same underlying cause into a single unified incident, suppresses recurring signals that match known flapping patterns, and deprioritizes low-severity notifications based on historical resolution patterns for similar alerts. The result is a much cleaner alert queue: engineers receive one actionable notification per real incident rather than dozens of redundant pages. Intelligent noise reduction is available on TaskCall's Digital Operations plan, ensuring that engineering teams get a calmer, more focused on-call experience backed by machine learning - without needing an enterprise contract to access it.